Splunk’s architecture
Splunk’s architecture comprises of components that are responsible for data ingestion and indexing and analytics.
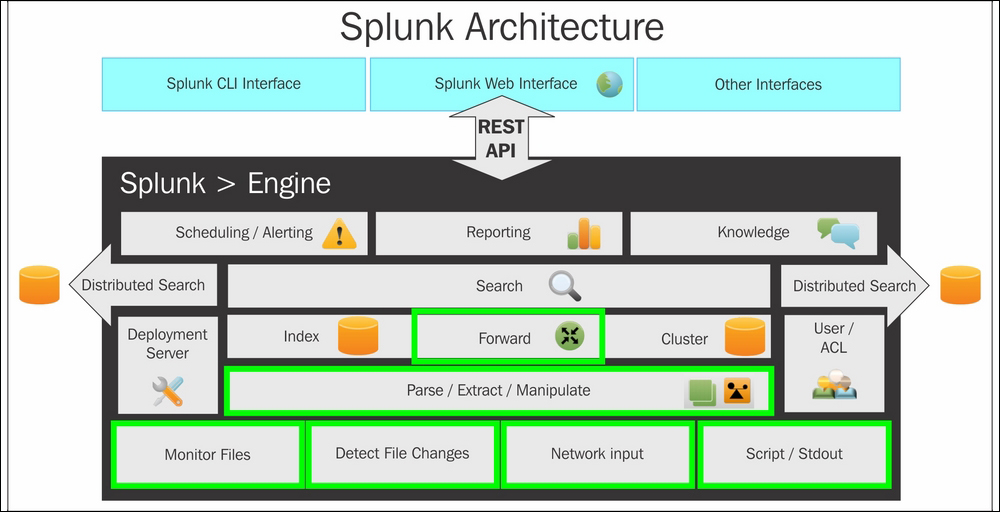
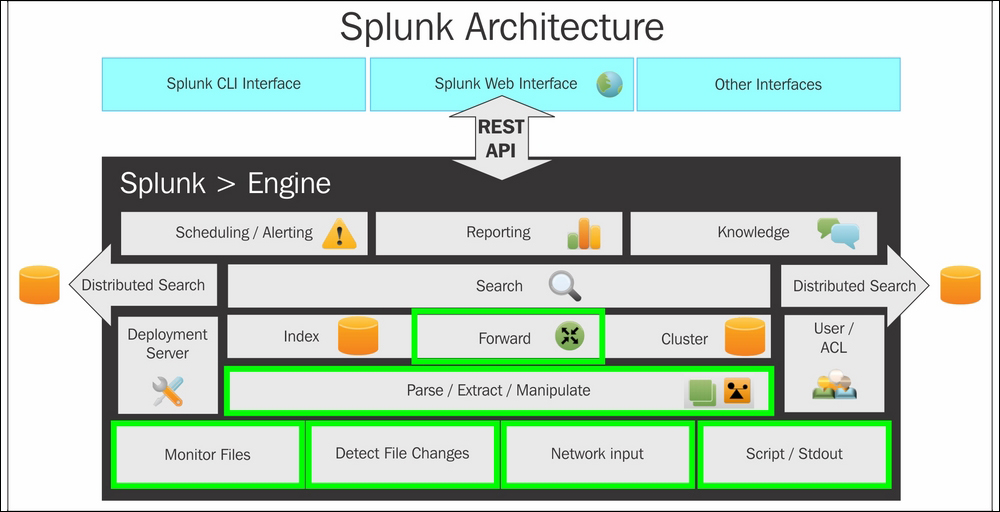
The lowest level of Splunk architecture depicts various data input methods supported by Splunk. These input methods can be configured to send data on Splunk indexers. Before the data reaches Splunk indexers, it can be parsed or manipulated, that is, data cleaning can be done if required. Once the data is indexed on Splunk, the next layer, that is, searching, comes into the picture for analytics over the log data.
Splunk supports two types of deployment: standalone deployment and distributed deployment. Depending on the deployment type, corresponding searches are performed. The Splunk engine has other additional components of knowledge manager, reporting and scheduling, and alerting. The entire Splunk engine is exposed to users via Splunk CLI, Splunk Web Interface, and Splunk SDK, which are supported by most languages.
Splunk installs a distributed server process on the host machine called splunkd. This process is responsible for indexing and processing a large amount of data through various sources. splunkd is capable of handling large volumes of streaming data and indexing it for real-time analytics over one or more pipelines.
Every single pipeline comprises of a series of processors, which results in faster and efficient processing of data. Listed below are the blocks of the Splunk architecture:

splunkd allows users to search, navigate, and manage data on Splunk Enterprise through the web interface called Splunk Web. It is a web application server based on Python providing a web interface to use Splunk. In the earlier version of Splunk, splunkd and Splunk Web were two separate processes, but from Splunk 6, both the processes were integrated in splunkd itself. It allows users to search for, analyze, and visualize data using the web interface. Splunk Web interface can be accessed using the Splunk web port, and Splunk also exposes the REST API for communication via the splunkd management port.
One of the important components of Splunk’s architecture is the data store. It is responsible for compressing and storing original (raw) data. The data is stored in Time Series Index (TSIDX) files. A data store also includes storage and archiving based on the configurable retention policy.
Splunk Enterprise deployments can range from single-server deployments (which index a few gigabytes of data per day and are accessed by a few users who are searching, analyzing, and visualizing the data) to large, distributed enterprise deployments across multiple data centers, indexing hundreds of terabytes of data and searches performed by hundreds of users. Splunk supports communication with another instance of a Splunk Server via TCP to forward data from one Splunk server to another to archive data and various other clustering and data distribution requirements via Splunk-to-Splunk TCP communication.
Bundles are the components of the Splunk architecture that store the configuration of data input, user accounts, Splunk applications, add-ons, and various other environment configurations.
Modules are those components of the Splunk architecture that are used to add new features by modifying or creating processors and pipelines. Modules are nothing but custom scripts and data input methods or extensions that can add a new feature or modify the existing features of Splunk.
Splunk’s traditional indexer had a single splunkd daemon running on a server that fetched data from different sources, which was then categorized into different indexes. Here, a traditional indexer refers to the indexers that were available in the older version of Splunk. The Splunk search queries are then processed by job queues depending on their priority. The indexer is capable of processing more searches. So, to utilize the underutilized indexer, there is need for parallelization. Parallelization leads to full utilization of the processing power of the indexer. Expanding Splunk to meet almost any capacity requirement in order to take advantage of the scaling capability of Splunk deployment requires parallel processing of indexers and search heads.
The following figure shows a traditional indexer host, where there is no parallelization and hence the indexer is left underutilized:

Index parallelization allows an indexer to have multiple pipeline sets. A pipeline set is responsible for processing data from ingestion of raw data, through event processing, to writing the events to a disk.
A traditional indexer runs just a single pipeline set. However, if the underlying machine is underutilized, both in terms of available cores and I/O, you can configure the indexer to run additional pipeline sets. By running multiple pipeline sets, you potentially double the indexer’s indexing throughput capacity. Increasing throughput also demands disks with high Input/output Operations Per Second (IOPS). So, hardware requirements should be taken into consideration while implementing parallelization.
When you implement two pipeline sets, you have two complete processing pipelines, from the point of data ingestion to the point of writing events to a disk. As shown in the following figure, there is a parallel process for each of the input method and each input is serviced by individual pipelines in the Splunk Server daemon. By enabling an indexer to create multiple pipelines, several data streams can be processed with additional CPU cores that were left underutilized earlier.
This implies that by implementing index parallelization, potentially more data can be indexed on a single indexer with the same set of hardware. It can accelerate parsing of data and writing to a disk up to the limit of indexers’ I/O capacity. Index parallelization can double the indexing speed in case of sudden increase of data from the forwarders.

Each pipeline set has its own set of queues, pipelines, and processors. Exceptions are input pipelines that are usually singleton. No states are shared across pipelines sets, and thus, there is no dependency or a situation of deadlock. Data from a single unique source is handled by only one pipeline set at a time. Each component performs its function independently.
The following are the various components of Splunk that are enhanced in Splunk 6.3 and they function as follows to support index parallelization:
- Monitor input: Each pipeline set has its own set of TailReaders, BatchReaders, and archive processors. This enables parallel reading of files and archives on forwarders. Each file/archive is assigned to one pipeline set.
- Forwarder: There will be one TCP output processor per pipeline set per forwarder input. This enables multiple TCP connections from forwarders to different indexers at the same time. Various rules such as load balancing rules can be applied to each pipeline set independently.
- Indexer: Every incoming TCP forwarder connection is bound to one pipeline set on the indexer.
- Indexing: Every pipeline set will independently write new data to indexes. Data is written in parallel for better utilization of underutilized resources. The buckets produced by different pipeline sets could have an overlapping time range.
Next, we’ll discuss how to configure multiple ingestion pipeline sets. To do that modify Server.conf located at $SPLUNK_HOME\etc\system\local as follows for a number of ingestion pipeline sets:
